

Unplanned downtime is costing the world’s largest companies $400 billion a year, or roughly 9% of their profits, a new report has found. This is the equivalent of about $9,000 lost for every minute of system failure or service degradation.
The report, published by the data management platform Splunk, also revealed that it takes 75 days for revenue for a Forbes Global 2000 company to recover to where it stood financially prior to the incident.
Downtime directly results in financial losses through lost revenue, regulatory fines and overtime wages for staff rectifying the issue. The report also unveiled hidden costs that take longer to have an impact, like diminished shareholder value, stagnant developer productivity and reputational damage.
The Hidden Costs of Downtime report surveyed 2,000 executives, including CFOs, CMOs, engineers, and IT and security professionals, from Global 2000 companies in 53 countries and a range of industries. They provided insight into where downtime originated, how it affected their businesses and how to reduce it.
Causes of downtime includes cybersecurity-related human errors
Downtime incidents experienced by large companies can be placed in one of two categories: security incidents (e.g., phishing attacks) or application or infrastructure issues (e.g., software failures). The average Global 2000 firm sees 466 hours of cybersecurity-related downtime and 456 hours of application or infrastructure-related downtime, according to the report.
“While availability for most systems is at multiple 9s, downtime across hundreds — or perhaps thousands — of systems adds up,” the authors wrote.
The number one biggest cause of downtime incidents cited by the respondents was cybersecurity-related human errors, such as clicking a phishing link. This was followed by ITOps-related human errors (e.g., infrastructure misconfigurations, capacity issues and application code errors). It takes an average of 18 hours until downtime or service degradation as a result of human error, like latency, is detected and a further 67 to 76 hours to recover.
SEE: How to Prevent Phishing Attacks with Multi-Factor Authentication
Software failure is the third leading cause of downtime, which becomes more of a risk as organisations adopt more complex development and deployment practices. Fourth is malware attack.
The report revealed that more than half of executives are aware of root causes of downtime in their organisations but choose not to fix them. This may be because they don’t want to increase the technical debt of legacy systems or have a plan to decommission the problematic application. Furthermore, only 42% of technology executives opt to have a postmortem after a downtime incident to isolate and alleviate the cause, as they can be difficult and time-consuming.

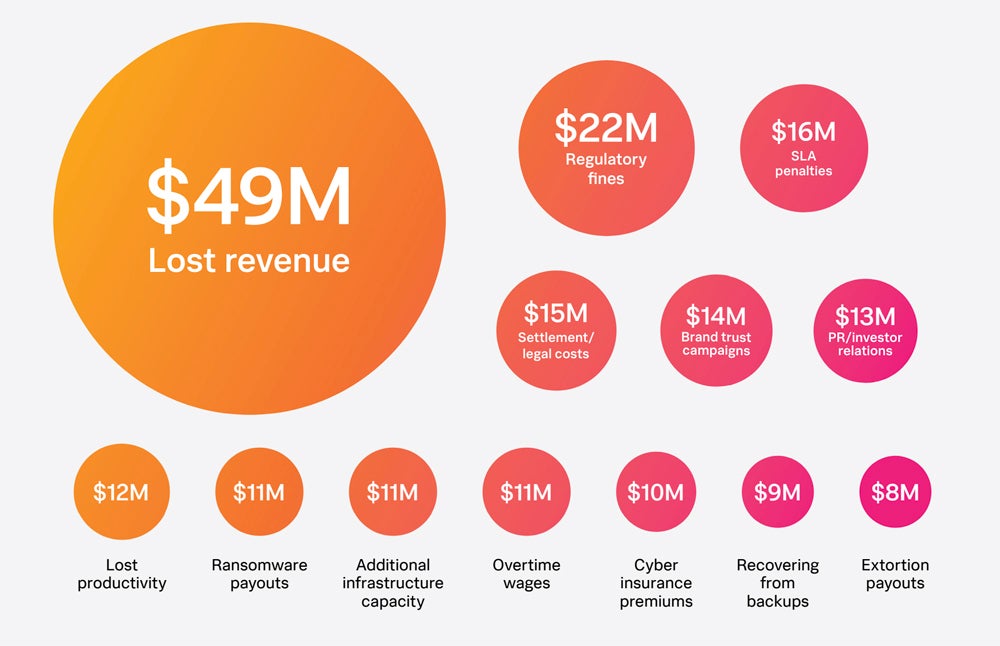
Direct costs of downtime
Lost revenue is by far the biggest cost as a result of a downtime event, at an average of $49 million a year for each Global 2000 company. The second largest is regulatory fines at $22 million, as many localities place strict regulations on downtime, such as the Digital Operational Resilience Act for the E.U.’s financial sector.
Other significant cost sinks include repairing the brand’s reputation. According to the CMOs, it costs an average of $14 million to conduct the necessary brand trust campaigns and another $13 million to repair public, investor and government relations. It takes about 60 days to fully restore the brand’s health.
Despite advice from cyber professionals, 67% of CFOs recommend their board of directors pay the ransom to get out of a ransomware attack, either directly to the perpetrator, through insurance, a third party or all three. Payouts cost Global 2000 companies a total of $19 million annually.
Hidden costs of downtime
Beyond the immediate financial costs of downtime, respondents cited a number of other costly ripple effects. For example, 28% said that a downtime event decreased their shareholder value, with an average of a 2.5% stock price drop. It took an average of 79 days for a large company’s stock to recover to where it was previously.
Other hidden costs of downtime events include delayed time-to-market and stagnated developer innovation, cited by 74% and 64% of respondents, respectively. The latter is a result of technical teams shifting from high-value work to applying patches and participating in postmortems. Similarly, in marketing departments, downtime results in teams and budgets being pivoted to crisis management, so productivity is lost in other areas.
Customer-lifetime value can also be affected by downtime, according to 40% of respondents, as an outage will negatively impact the customer experience and, therefore, their loyalty to the organisation. In fact, 29% of surveyed companies say they know they have lost customers as a result of an incident.
SEE: What the AT&T Outage Can Teach Organizations About Customer Communication and IT Best Practices
How businesses can avoid downtime
Tips from resilience leaders
The Splunk report revealed a number of ways that companies can avoid downtime, either because respondents deemed them helpful or they were demonstrated by the top 10% of companies demonstrating resilience to outages.
Companies in the latter category, so-called “resilience leaders,” retain $17 million more of their revenue, pay $10 million less in fines and save $7 million on ransomware payouts. They also recover 23% and 28% faster than average from cybersecurity and application or infrastructure-related downtime, respectively. Hidden costs, like poor customer experience, have less of an impact as a result.
Resilience leaders invest more in certain areas than other organisations surveyed, and these are:
- Security tools: $12 million more.
- Observability tools: $2.4 million more.
- Additional infrastructure capacity: $8 million more.
- Cyber insurance premiums: $11 million more.
- Backups: $10 million more.
Generative AI can also be used to reduce downtime, as it can equip teams with the information they need to get back online quickly. The report found that resilience leaders expand their use of AI features four times faster than other respondents. Furthermore, 74% of firms that use discrete AI tools and 64% who embed AI into existing tools, to address downtime deemed it beneficial.
Tips from Splunk
The reports’ authors also provided tips to avoid downtime based on their expertise.
- Have a downtime plan. Instrument every app, follow a runbook for outages and identify owning engineers. Practice tabletop exercises and drills.
- Perform postmortems. Observability tooling makes it easier to isolate root causes and implement fixes.
- Establish a clear data governance policy. Rules regarding intellectual property, especially when it comes to inputting it into large language models, will safeguard the organisation from data leakage.
- Connect teams and tools. Teams that share tools, data and context will have an easier time collaborating, fixing the problem and identifying the root cause of downtime.
- Employ predictive analytics. AI- and ML-driven solutions can recognise patterns and alert teams when downtime may occur.
“Disruption in business is unavoidable. When digital systems fail unexpectedly, companies not only lose substantial revenue and risk facing regulatory fines, they also lose customer trust and reputation,” said Gary Steele, President of Go-to-Market for Cisco and GM at Splunk, in a press release.
“How an organisation reacts, adapts and evolves to disruption is what sets it apart as a leader. A foundational building block for a resilient enterprise is a unified approach to security and observability to quickly detect and fix problems across their entire digital footprint.”
